方案描述:
(1) 提出了一个基于深度学习的护目镜佩戴检测算法:
通过对深度残差网络模型的研究,结合护目镜佩戴检测的具体使用场景,我们在原有深度残差网络的基础上,增加了池化层 MAXPOOL和非线性激励层RELU,减少网络参数,提高了网络的不变性。引入Dropout机制,极大地减缓了过拟合现象的发生,提高了模型预测护目镜佩戴情况的准确率。同时,结合护目镜与普通眼镜在特征上的相似性,引入了包含普通眼镜分类的预训练模型,对护目镜佩戴情况的检测准确率有很大帮助。
(2) 建立一个护目镜佩戴图像数据集:
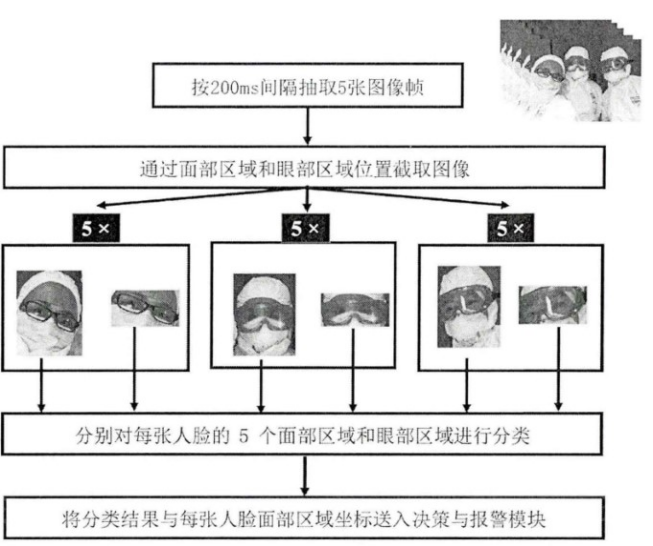
由于在护目镜佩戴情况检测过程中,人脸面部区域的大小、眼部区域的大小、摄像头拍摄时的角度和距离、光照和遮挡情况,都会对人脸检测和护目镜佩戴情况的分类造成影响,选取了各类情况下(室内/室外,不同光照条件,不同角度,不同遮挡情况)的真实场景图像。同时,由于护目镜佩戴图像的数据量较小,开发一种基于人脸特征点的护目镜佩戴图像合成算法,分别生成左右两半部分的贴合人脸的护目镜图片,给各类人脸图像中的人物“佩戴”护目镜,一定程度上丰富了数据集,提高了护目镜佩戴检测算法的泛化能力。标注完成后,共在1607张可能包含多张人脸的图像中得到了3108张面部区域及眼部区域图像。









 粤公网安备 44030502003347号
粤公网安备 44030502003347号